Neural and Computational Mechanisms Underlying One-shot Perceptual Learning in Humans
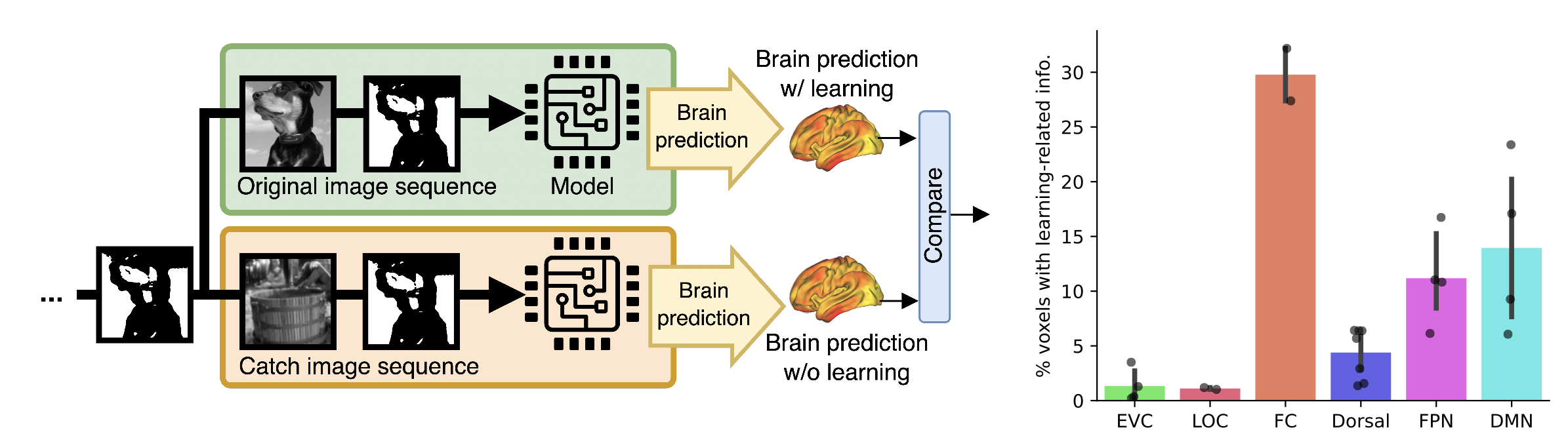
In this paper, we investigate the neural and computational mechanisms underlying one-shot perceptual learning in humans. By introducing a novel top-down feedback mechanism into a vision transformer and comparing its representations with fMRI data, we find high level visual cortex as the most likely neural substrate wherein neural plasticity supports one-shot perceptual learning.
